Abstract
Human action-reaction synthesis, a fundamental challenge in modeling causal human interactions, plays a critical role in applications ranging from virtual reality to social robotics. While diffusion-based models have demonstrated promising performance, they exhibit two key limitations for interaction synthesis: reliance on complex noise-to-reaction generators with intricate conditional mechanisms, and frequent physical violations in generated motions. To address these issues, we propose Action-Reaction Flow Matching (ARFlow), a novel framework that establishes direct action-to-reaction mappings, eliminating the need for complex conditional mechanisms. Our approach introduces a physical guidance mechanism specifically designed for Flow Matching (FM) that effectively prevents body penetration artifacts during sampling. Moreover, we discover the bias of traditional flow matching sampling algorithm and employ a reprojection method to revise the sampling direction of FM. To further enhance the reaction diversity, we incorporate randomness into the sampling process. Extensive experiments on NTU120 and Chi3D datasets demonstrate that ARFlow not only outperforms existing methods in terms of Fréchet Inception Distance and motion diversity but also significantly reduces body collisions, as measured by our new Intersection Volume and Intersection Frequency metrics.
Overview
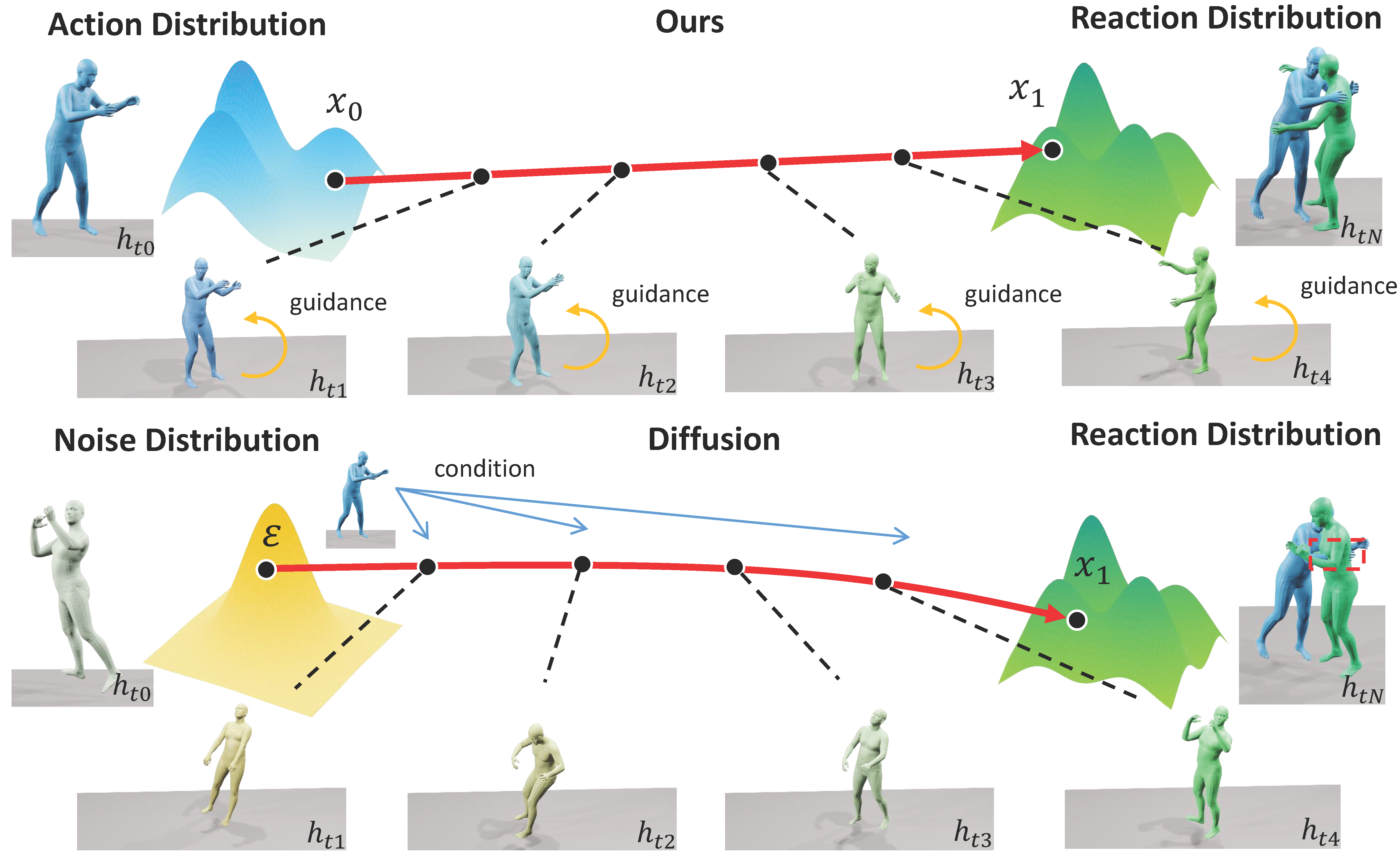
Our proposed Human Action-Reaction Flow (ARFlow). We directly establish a mapping between the action and reaction distribution and our sampling process is further guided by our physical constraint guidance. The change of colors represents the variation of the h-frame reaction with sampling timestep t.
Pipeline
Pipeline of ARFlow. (a) For a sampled timestep t, we linearly interpolate a coupled action-reaction pair to produce the intermediate state xt, which is then turns into a d-dimensional latent feature through a linear layer. We use Transformer Decoder Units to directly predict clean reaction motions. (b) After training the networks in (a), our ARFlow uses them for x1-prediction based sampling. The sampling process is further guided by the gradient of L to generate physically plausible reactions.
Results (with a failure case)
As shown, our method not only produces more physically plausible reactions but also more responsive reactions due to stronger modeling ability for causal relationship between actions and reactions. Blue for actors and Green for reactors.
Comparison with Baselines
We provide a qualitative comparison of reaction sequences generated by MDM, ReGenNet and ARFlow with physical constraint guidance. Both MDM and ReGenNet produce varying degrees of penetration between the actor and the reactor. In contrast, ARFlow produces more responsive and physically plausible reactions. Here are some comparative videos:
Whisper
MDM
ReGenNet
✅ARFlow
Kick
MDM
ReGenNet
✅ARFlow
Drink
MDM
ReGenNet
✅ARFlow